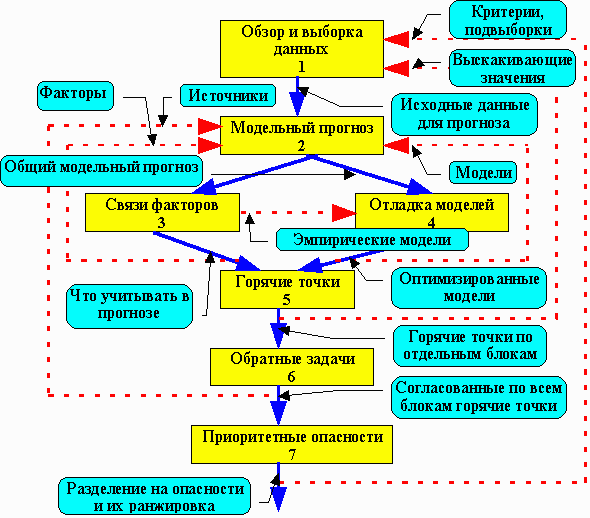
Все возможные функции системы упорядочены в несколько режимов. Режим - это подборка логически связанных операций обработки, приводящих к какому - либо "промежуточному финишу". Разбивка на режимы преследует две цели:
облегчить неискушенному пользователю структуризацию его задачи и правильное прохождение последовательности этапов обработки;
Нахождение в одном режиме не препятствует доступу к любым операциям других режимов через меню и некоторыми другими способами. Однако кнопки главного экрана, предназначенные для неискушенного пользователя, показываются только в соответствии с одним выбранным режимом.
Семь основных режимов можно выстроить в следующую (нежесткую) последовательность, которая позволяет упорядочить решение основных практических задач, стоящих перед пользователями, и дает своего рода общую методику обработки данных.
Желтые блоки - основные режимы. Голубые блоки - основные выходы информационных режимоы.
Пунктирные линии - возврат в итерационные процессы.
Выборка исходных данных для модельного прогноза и реперных данных, к которым будут привязываться прогнозные значения. Очистка от выскакивающих значений согласно текущим критериям, определяющим понятие выскакивающего значения.
Обсчет выборки для всех блоков, обеспеченных данными, с передачей информации вперед по конвейеру блоков и с взаимной подгонкой результатов расчета и реперных наблюдений. В результате получается прогноз будущей заболеваемости во времени, интерполяция концентраций в пространстве между станциями наблюдения и т.п.
Поиск эмпирических моделей, связывающих между собой данные из разных блоков или разные факторы (т.е. координатные интервалы) из одного блока. Включает корреляционный анализ для отбора связываемых факторов, кластерный анализ для расслоения выборки на части с разным типом связи, паттерн-анализ для построения качественной модели связи, регрессионный анализ для построения количественной модели связи. Примеры результатов: разбивка на территории со сходным паттерном многолетней динамики заболеваний; зависимость заболеваемости с определенным диагнозом от величины риска по определенному загрязнителю и т.п. По результатам, возможно, потребуется повторить этап модельного прогноза с новой подвыборкой или новым набором учитываемых факторов.
Подгонка параметров предметных моделей (или эмпирических моделей, построенных на предыдущем этапе) так, чтобы оптимизировать критерий качества модели. Критерием обычно служит согласие моделей с данными или между собой, а также устойчивость модельного прогноза к вариациям неконтролируемых факторов. Включает также выбор из нескольких альтернативных моделей, например ОНД-86 или ISC3. Примеры результатов: подбор коэффициентов, определяющих атмосферную устойчивость; подбор сценариев экспозиции в разных группах; выбор из альтернативных регрессионных моделей, построенных по одним и тем же данным. По результатам, возможно, придется повторить этап прогноза с новыми параметрами модели.
Поиск горячих точек - выделяющихся, сгруппированных и устойчивых значений концентрации, заболеваемости и т.д. Производится отдельно в каждом блоке по его переменной значения, причем как для модельного прогноза, так и для данных наблюдений. Производится с учетом всех переменных блока: времени, территории и т.д. Результат: подвыборка из достоверных горячих точек, например «неблагоприятные метеоусловия там-то и тогда-то», устойчивые очаги заболеваемости и т.д.; подвыборка из достоверных фоновых значений и подвыборка из недостоверных значений. Последняя может быть отброшена с возвратом к этапу построения новой выборки. Горячие точки должны образовывать причинно-следственную цепочку, проходящую через несколько блоков, например «повышенный выброс - повышенная концентрация - повышенный риск - повышенная заболеваемость». Эта цепочка проверяется и корректируется на следующем этапе.
Поиск источников для тех горячих точек, у которых на предыдущем этапе не были выявлены горячие точки - «причины». Производится просчет по конвейеру блоков в обратном направлении. По результатам может быть необходимо повторить все этапы, начиная с модельного прогноза, для построения моделей, связывающих источники и их «следствия» и уточнения моделей, построенных ранее для «смеси» фона и горячих точек. В результате выборка разбивается на несколько «опасностей» - цепочек горячих точек из разных блоков, связанных моделями.
Ранжировка опасностей по важности, согласно введенным пользователем критериям, в т.ч. весам, придаваемым разным блокам. Одновременно из всех созданных на предыдущих этапах вариантов выбираются наиболее достоверные. По результатам может потребоваться возврат к первому этапу для сосредоточения расчета на подвыборке, соответствующей только одной из опасностей.